Combining natural language processing and multidimensional classifiers to predict and correct CMMS metadata
Abstract
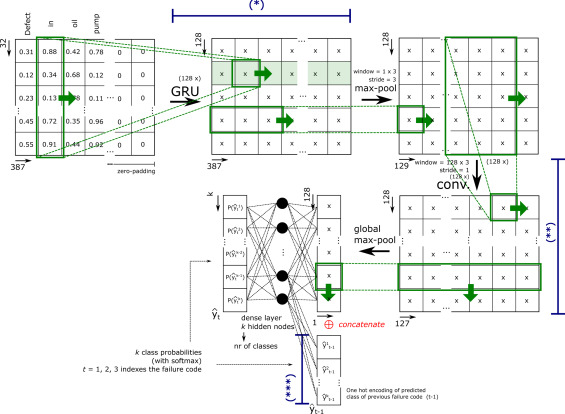
Computerized maintenance management systems (CMMSs) contain valuable data on the maintenance operations in an organization. A large part of these data consists of unstructured, written texts contained in failure notifications which are generated each time an unexpected failure occurs, enriched with structured metadata consisting of a number of labels that allow to categorize the failures, such as the type of failure, its cause or the corrective action that was taken. In this paper, we show that natural language processing techniques can be used to predict the structured metadata based on the unstructured text and even identify mislabeled notifications or ambiguous labels. Specific attention is given to the complexity that arises from the highly technical nature of the texts combined with a telegraphic writing style and heavy use of sentence fragments and abbreviations. Moreover, it is shown that exploiting dependencies between different components of the metadata, and regarding the prediction problem as a multidimensional classification problem, can improve the reliability of the predicted labels. We illustrate and test our label prediction pipeline on the CMMS data of a large pharmaceutical company.